Decoding Spam: A Machine Learning Journey to Detect and Defeat Fraudulent Emails
Decoding Spam: A Machine Learning Journey to Detect and Defeat Fraudulent Emails
Summary
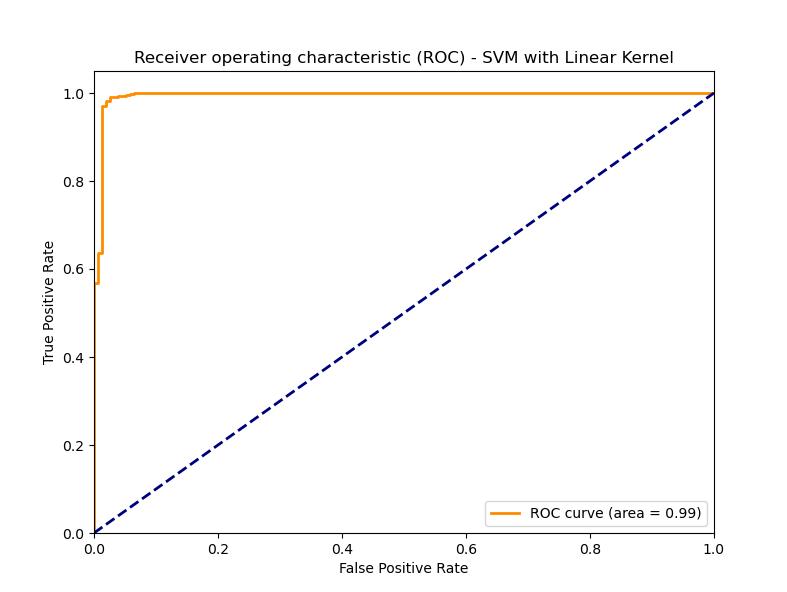
In this analysis, a comprehensive comparison of six machine learning models was conducted to identify the most effective spam detection algorithm. The models included Logistic Regression, Naive Bayes, K-Nearest Neighbors (KNN), Decision Tree, Random Forests, and Support Vector Machines (SVM). The analysis used key metrics such as accuracy, precision, recall, and the F1 score to evaluate the models. The Receiver Operating Characteristic (ROC) curve was plotted for each model to visually represent their performance in distinguishing spam from legitimate emails. The Support Vector Machines (SVM) model emerged as the best-performing model, with a high AUC (Area Under the Curve) of 0.99, indicating excellent classification performance. Given its superior accuracy and discriminative ability, SVM was selected as the core model for building a web-based spam detection application.
Key Process Steps
- Data Acquisition: Collecting and labelling email datasets with spam and non-spam labels.
- Data Preprocessing: Cleaning the data to ensure efficient processing by the machine learning algorithm.
- Model Comparison: Evaluating six models based on performance metrics.
- Model Selection: Selecting SVM as the best model based on accuracy and AUC score.
- Web Application Development: Using Flask to build a web interface that allows users to input email text and classify it as spam or legitimate.
- Evaluation and Visualization: Displaying performance using ROC curves and metrics such as accuracy, precision, recall, and F1 score.
Comparative Analysis of Detection Models
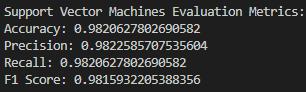
This research investigates the performance of six machine learning models: logistic regression, naive bayes, K-nearest neighbours, decision tree classifiers, random forests, and SVMs (support vector machines). The performance of each model is meticulously assessed using various metrics: accuracy, precision, recall, and the F1 metric. Such metrics give information on how effective each classifier is at discriminating spam from ham emails. The accuracy is the ratio of truly predicted observations to the total observations. Accuracy is the proportion of correctly predicted positive observations to the overall predicted positive ones. Classification, also known as sensitivity, is the measure of correctly predicted positive observations over all observations in the actual class. The F1 score is the weighted mean of precision recall, which gives a single measure of the accuracy of the test(Sokolova and Lapalme, 2009).
1.Logistic Regression
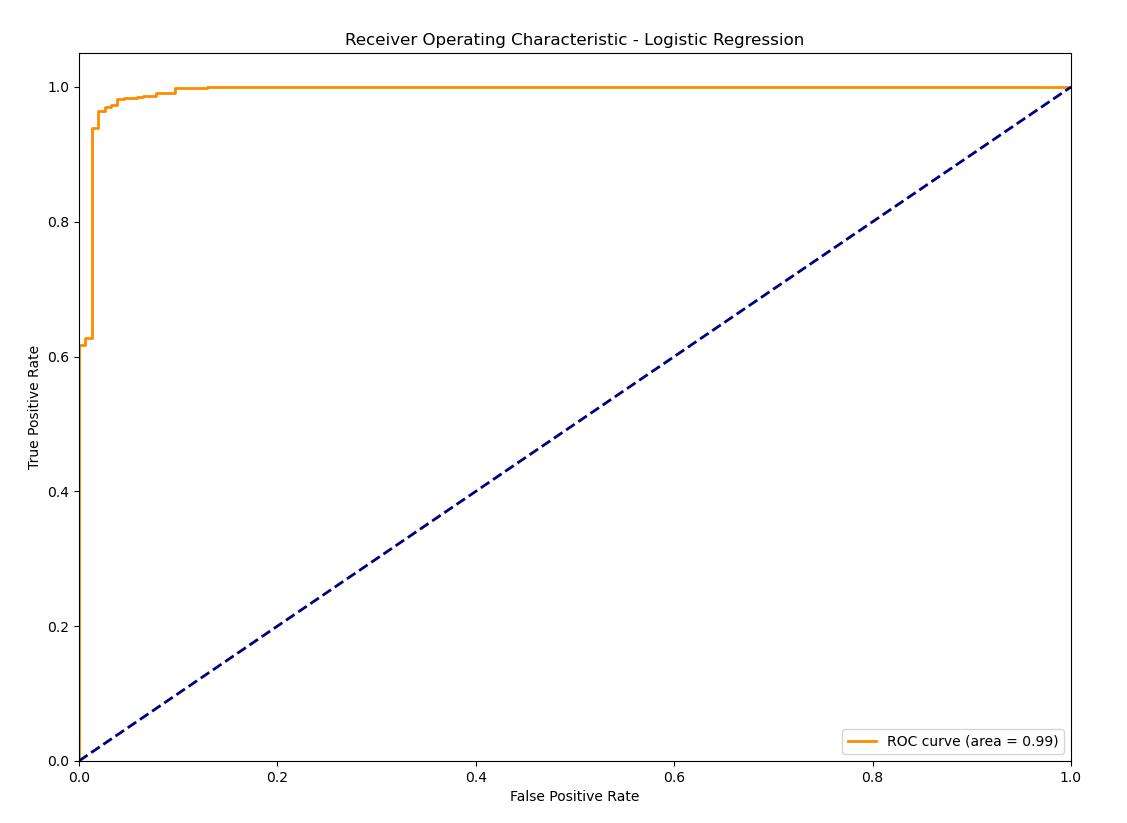
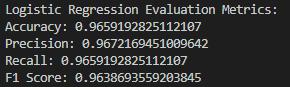
The ROC curve shows Logistic Regression a high area under the curve (AUC), revealing a good performance in terms of distinguishing spam from ham emails. The curve follows the upper left corner quite well, which means the true positive rate and false positive rate are in a balance. Logistic Regression is an excellent method, providing a high accuracy along with balanced metrics, and therefore, it can be safely used for binary classification tasks.
- Naive Bayes
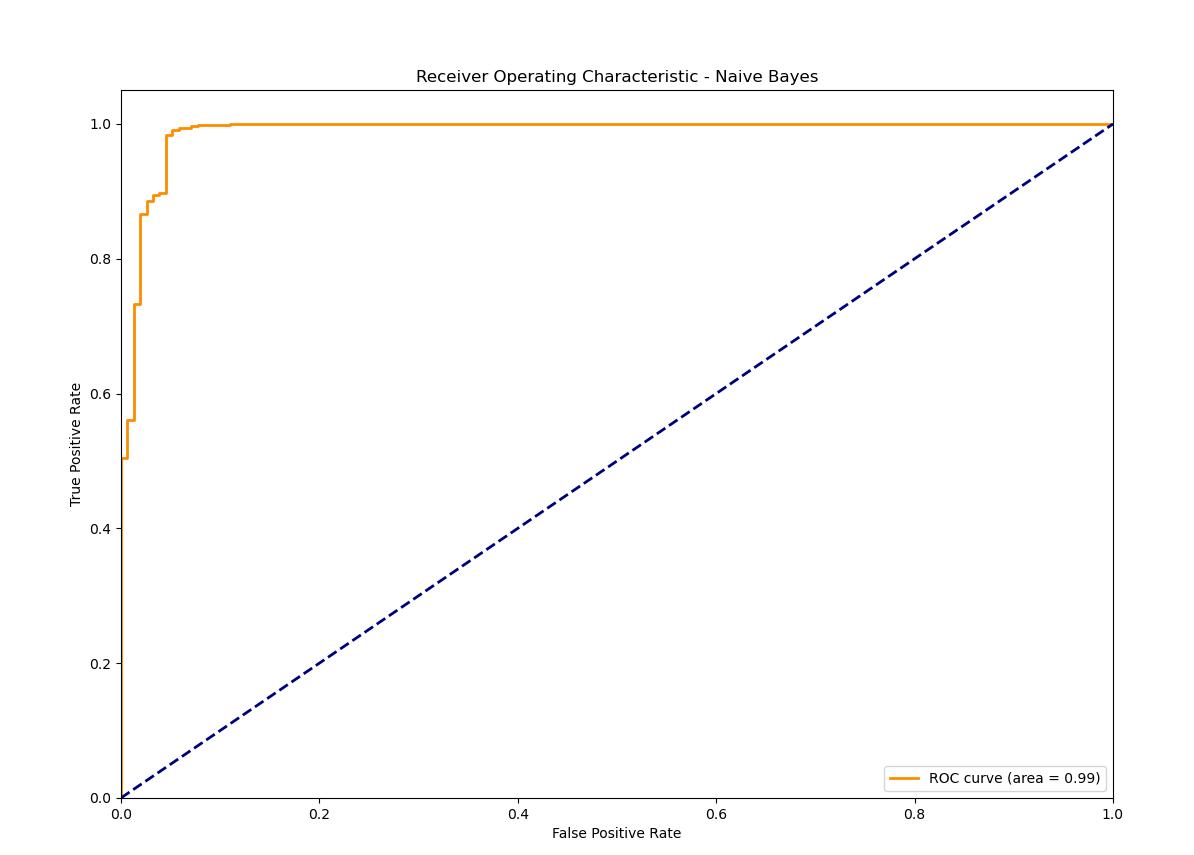
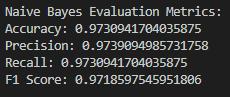
ROC Plot: The ROC curve of the Naive Bayes model actually gives a higher AUC than the Logistic Regression model, and so it is marginally better at differentiating spam and ham. The capability of applying text classification through this approach is largely attributable to that assumption of feature independence. Naive Bayes achieves the best results and outperforms Logistic Regression slightly in all metrics, which is evidence of its ability to classify texts correctly, especially due to it assuming the independency of features.
- K-Nearest Neighbors (KNN)
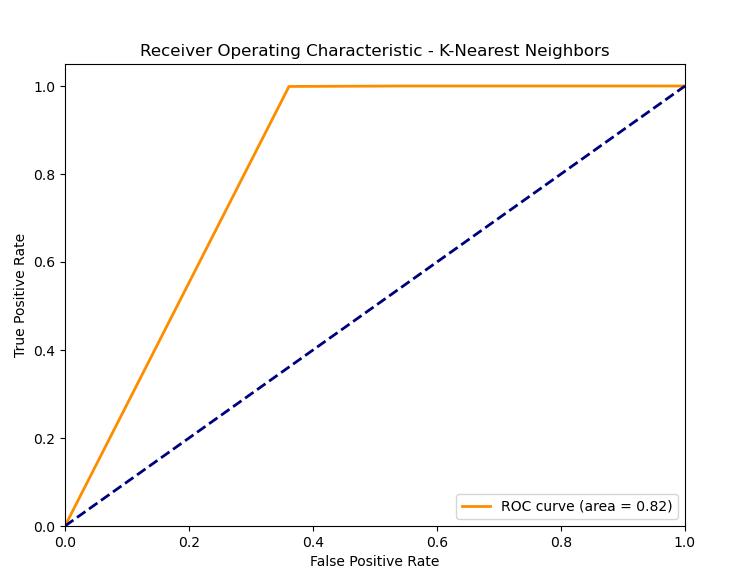
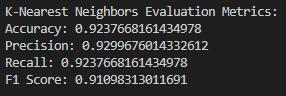
ROC Plot: The AUC of ROC curve for KNN is less than the others models, it can be inferred that KNN is not the best suited model for this task. There could be a possibility of this because KNN uses the proximity of the similar data points to reach the decision, which is not less difficult for the text data due to the high dimensional space. K-Nearest Neighbors has lower scores in comparison to other models. This might be the case, since it often uses the closeness of similar data points that is not a very efficient way when it comes to high dimensional text data.
- Decision Tree
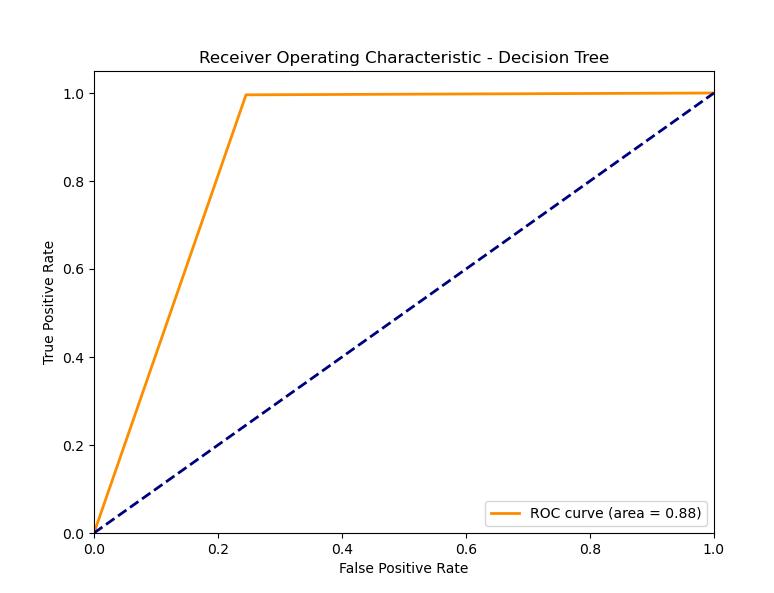
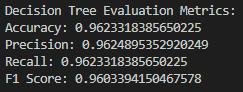
ROC Plot: It has a good ROC curve, with the AUC being not as good as some other models. This might indicate a satisfactory but not outstanding result: maybe a decision boundary could be too simple or the network overfits. The decision tree model is a robust model that is both accurate and generalizes well. Hence, this model somewhat slackens its performance in comparison with others, maybe because of overfitting or the simplicity of the decision boundaries.
- Random Forests
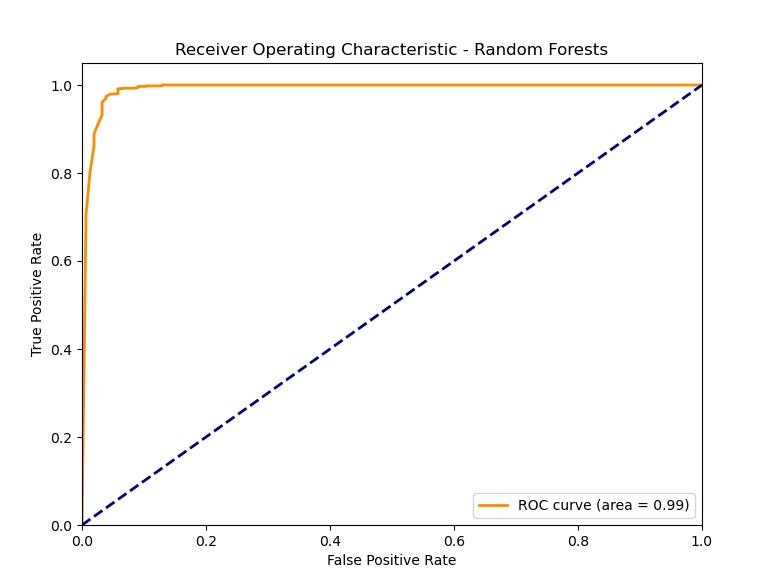
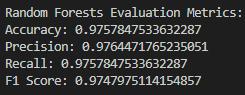
ROC Plot: The Random Forest model is characterized by the highest AUC score among the models under consideration, which implies high accuracy in classification. The superiority of this model is based on the ensemble approach, which consequently will provide more robustness and reduce the probability of an overfitting occurrence. The Random Forests surpass the Decision Tree model by means of an ensemble of trees, which substantially boost precision and immunity to overfitting.
- Support Vector Machines (SVM)
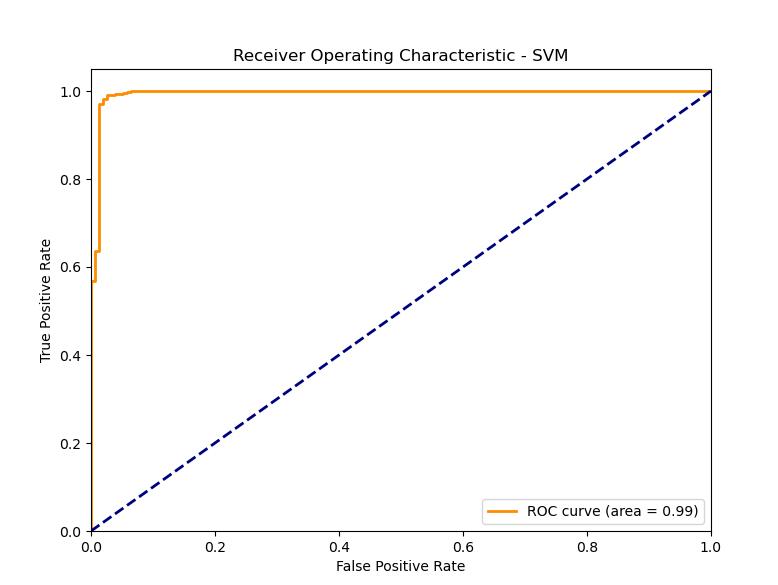
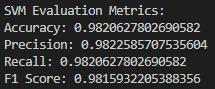
ROC Plot: The SVM model is the strongest in terms of the ROC curve, as the curve shows the highest AUC, indicating the best distinction among spam and ham emails. This unique capability can be attributed to its mechanism of coming up with the best hyperplane that maximally dissects the two classes. SVM reached the best results on all measures, proving it is able to generate the best hyperplanes for such problems through linear kernels.
Evaluating the SPAM Email Detection System
In the context of a spam email detection application, the process involves several methodical steps using machine learning algorithms, specifically Support Vector Machines (SVM) with a linear kernel. This was built with the different models to evaluate the accuracy, and the Support Victor machine was the best model when compare the accuracy because of that SVM was the selected model to build this application.
These steps are as follows:
- Data Acquisition: Gathering and labelling a dataset that includes both spam and non-spam emails, crucial for training and evaluating the machine learning model.
- Data Preprocessing: Cleaning and transforming the text data to enable the learning algorithm to process the information effectively. This includes normalization, tokenization, and feature extraction.
- Model Selection: Choosing an appropriate machine learning model to classify emails. Support Vector Machines (SVM) are chosen for their effectiveness in high-dimensional spaces and their ability to model non-linear decision boundaries using different kernels.
- Model Training: Utilizing the “sklearn” library's SVC class with a linear kernel to train the SVM model on the pre-processed training data. Training involves adjusting the model parameters to minimize prediction errors.
- Prediction: Finally, the trained SVM model is applied to make the decisions on the class (spam or non-spam) of new email entries. Predictive accuracy has been recognized as the main performance evaluation indicator.
- Evaluation: The assessment metrics of accuracy, precision, recall, and the Receiver Operating Characteristic (ROC) curve can be used in such a way. The ROC curve is a plot that represents the true positive rate versus the false positive rate at various cut-off values, and area under curve (AUC) serves as an index of the model's ability to distinguish between the classes.
- Performance Visualization: Tracing the ROC curve using matplotlib, highlighting the model's performance in spam detection. A model which has an AUC close to 1.0 is a good performer.
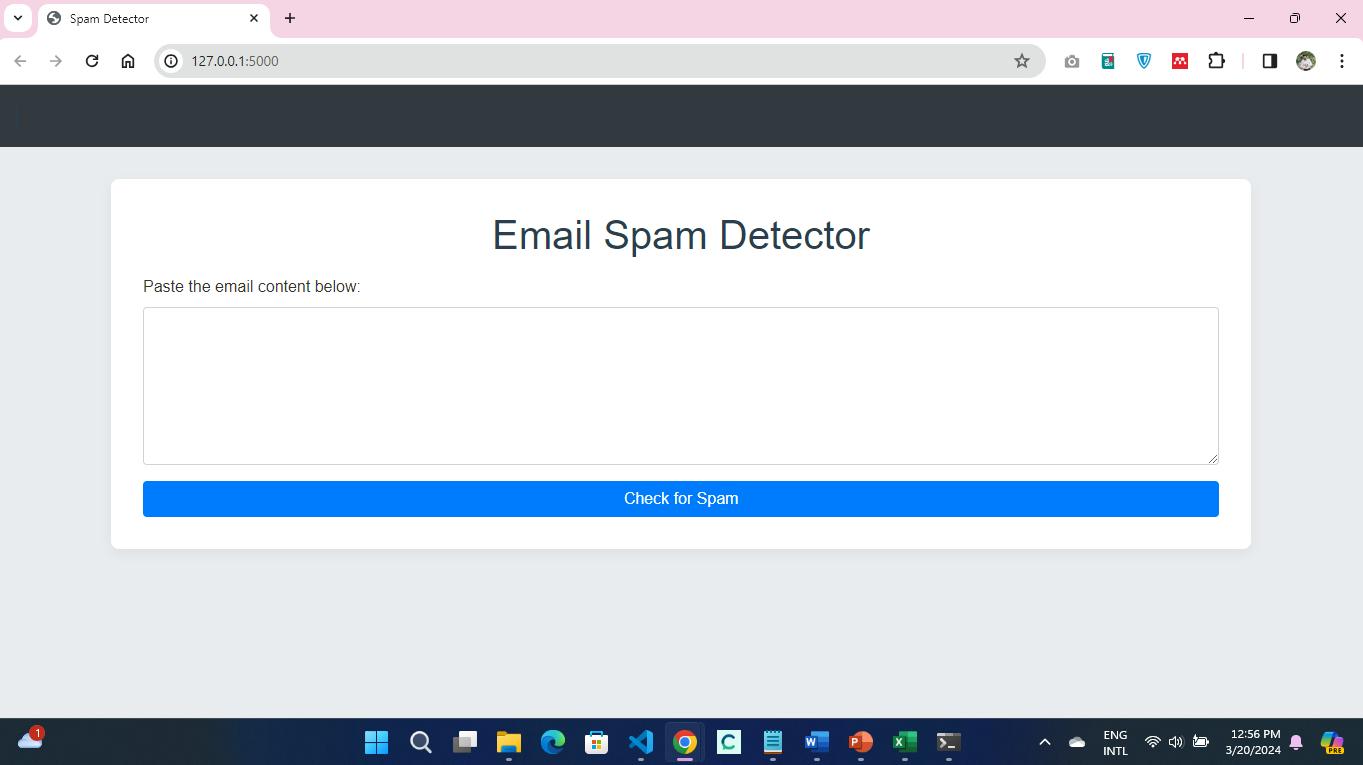
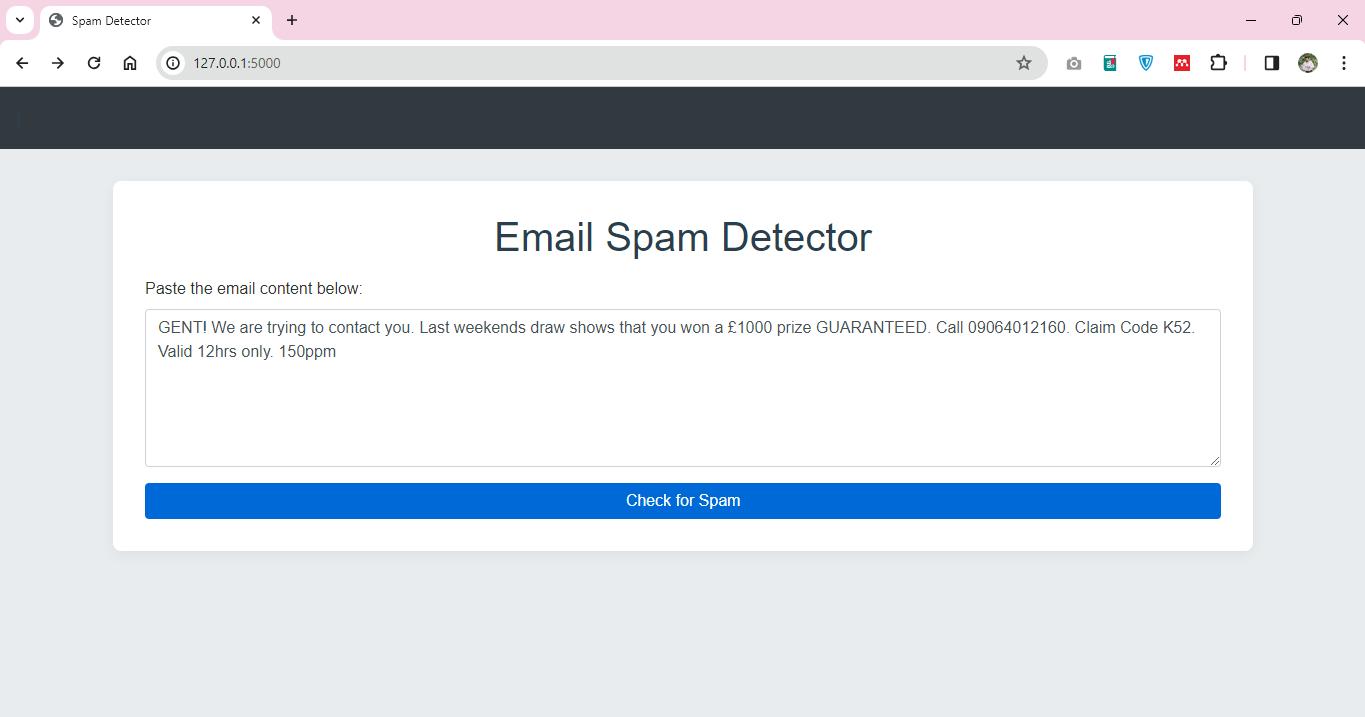
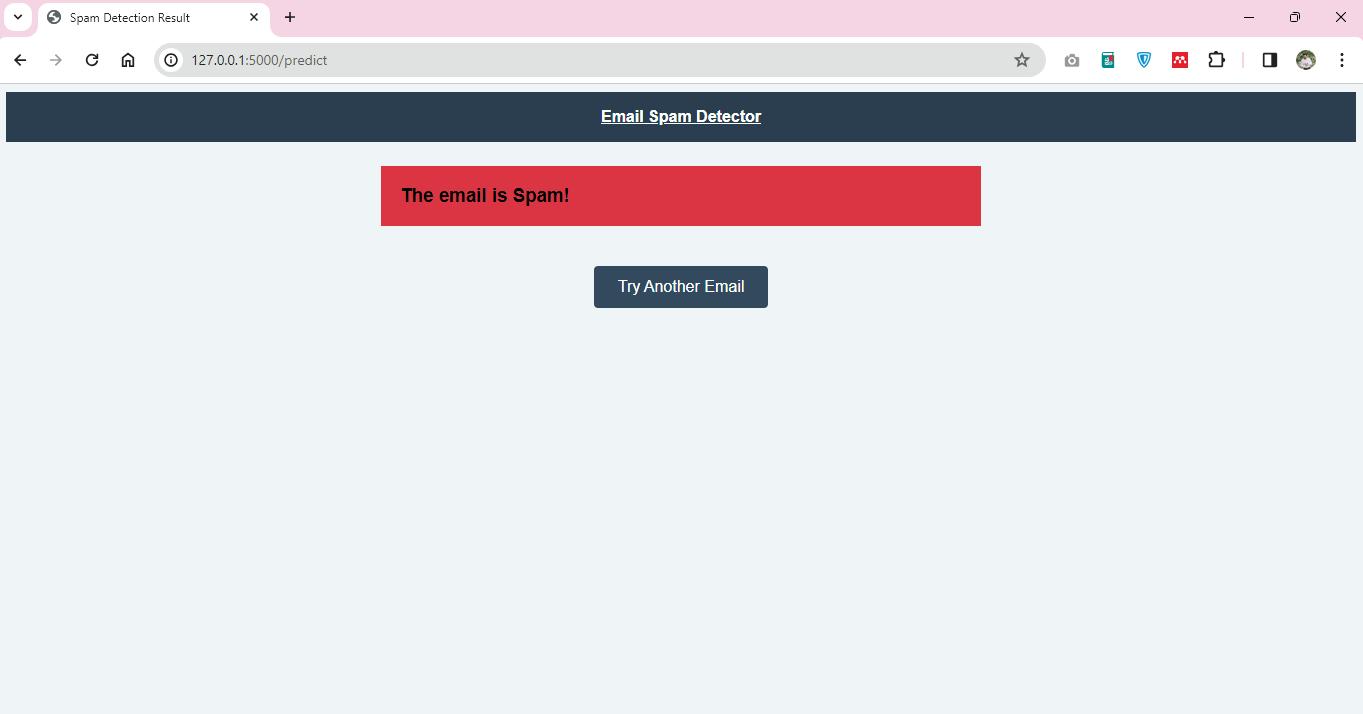
The spam detection application will provide users with a box where they will be required to enter the contents of an email, which will then be processed through an SVM classification model. The web application is the interface used to display the classification results, which are either classified as spam or legitimate. The application operates on a local server, as denoted by the IP address 127.0.0.1:5000, which indicates that the application was developed on the local server for development purposes. In this regard, it uses a web framework, presumably Flask, for its backend operations, which is the popular option for such tasks because of its lightweight and flexible nature.
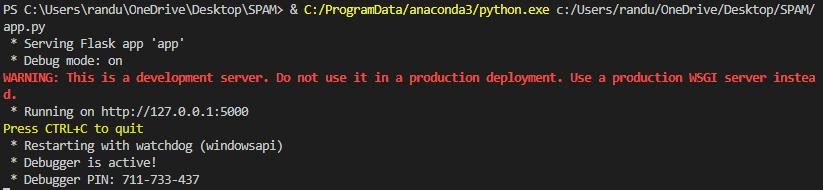
When executing the spam detection application, the following output is generated in the console, indicating that the Flask app named 'app' is in active development mode and running on the local server. Debug mode in Flask enables the coders to see the changes to the code in real-time while the server is running and offers an in-browser debugger for problem-solving.
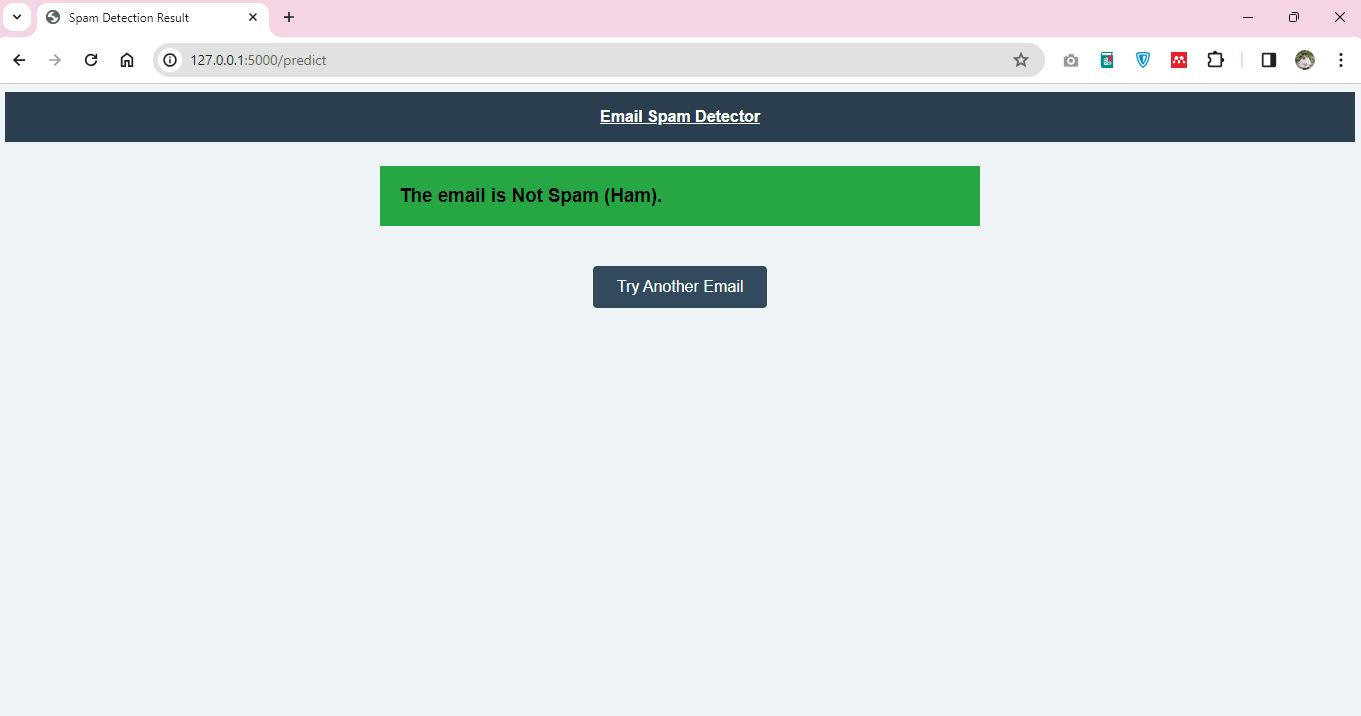
SCAM Email detector Web base App “app.py” file:
IDE - Visual Studio Code
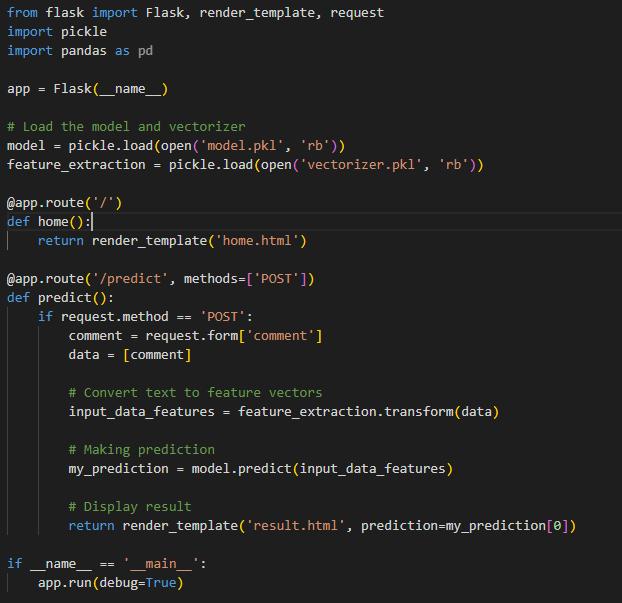
train_model.py file
File Structure
Dataset Analysis
SARIMAX model Training : IDE - Visual Studio Code
ARIMA model
Sampel of Heat map visualization
IDE - Jupyter Notebook
Conclusion
The SVM model was chosen for its high accuracy and low false positive rate, making it suitable for spam detection. The developed web application provides users with an easy interface to check email authenticity, enhancing cybersecurity against spam emails. Future research can focus on improving model accuracy to adapt to evolving spam techniques.